
Individualsoftware: Definition, Beispiele und was im Vertrag stehen muss
Was ist Individualsoftware? Definition, echte Beispiele und die Vertragsfragen, die über Erfolg entscheiden: Festpreis, Quellcode-Eigentum, Exit.

ZIM-Förderung gestoppt: Was KMU jetzt tun können
ZIM-Förderung gestoppt seit 7. Juli 2026: Was mit laufenden Anträgen passiert, wie die Forschungszulage einspringt und was bis 2027 zu tun ist.
Geschäftsprozesse digitalisieren: Vorgehen, Methoden und Make-or-Buy
Geschäftsprozesse digitalisieren: von der Ist-Analyse über Process Mining und BPMN bis zur Make-or-Buy-Entscheidung. Der Leitfaden für den Mittelstand.

Digitalisierung im Mittelstand: Der Leitfaden 2026
Digitalisierung im Mittelstand 2026: Reifegrad bestimmen, Prozesse und Produktion digitalisieren, Förderung nutzen und in 6 Schritten zur Roadmap.
MongoDB 8 stirbt leise - wenn die CPU die Datenbank für einen Angreifer hält
MongoDB 8 crasht auf Ubuntu 26.04 mit Kernel 7.0 und AMD Zen 4/5 ohne Fehlermeldung, weil CET Shadow Stack den Fiber-Pivot für einen Exploit hält. Der Fix ist eine Zeile im Docker-Compose.

Caches sind keine Lösung
Ein Cache, den du nicht ausschalten kannst, ist kein Cache. Warum Caching keine Lösung ist — und du zuerst das eigentliche Problem fixen musst.
Shadow Tech Debt — die unsichtbare Schuld der KI-Agenten
Shadow Tech Debt entsteht, wenn KI-Agenten Code schreiben, der die Architektur schleichend zerlegt. So helfen Leitplanken und Blueprints.
Unsere AI-Strategie - wie die Neckar IT Software entwickeln wird
Die AI-Strategie der Neckar IT: Software-Produktion vollständig automatisieren. Warum KI als Maschine gedacht werden muss, nicht als Assistent.
Vor Ort bei BraunBeton: Unsere KI-Objekterkennung im Einsatz
Wie sieht ein KI-Objekterkennung System in der Praxis aus? Wir zeigen den kompletten Hardware-Aufbau (Kameras, Licht) bei BraunBeton.

KI Qualitätskontrolle: Wie unsere Software Fehler in Echtzeit erkennt
KI Qualitätskontrolle in der Produktion: Wie automatisierte Bilderkennung Fehler in Echtzeit erkennt – mit Live-Dashboard, Heatmaps und Reports.
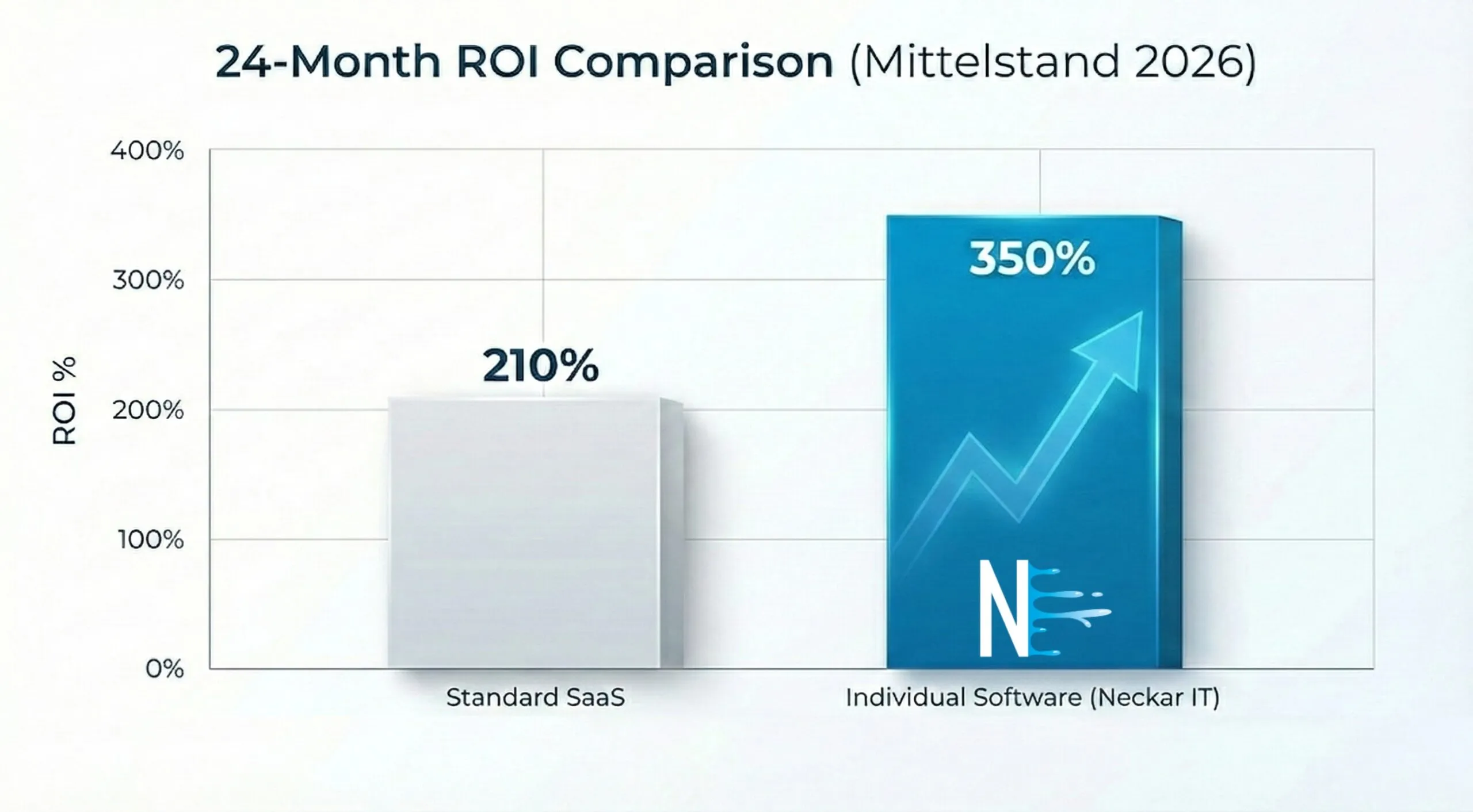
Prozessautomatisierung im Mittelstand: Leitfaden 2026
Prozessautomatisierung im Mittelstand: Welche Prozesse sich 2026 lohnen, ROI bis 350 % und passende Förderung. Der Praxis-Leitfaden.
Datenvisualisierung ist entscheidend für Ihr Unternehmen!
Datenvisualisierung Software für KMU: Warum eigene Dashboards oft günstiger sind als Power-BI-Lizenzen — mit Vergleich und Praxisbeispiel.
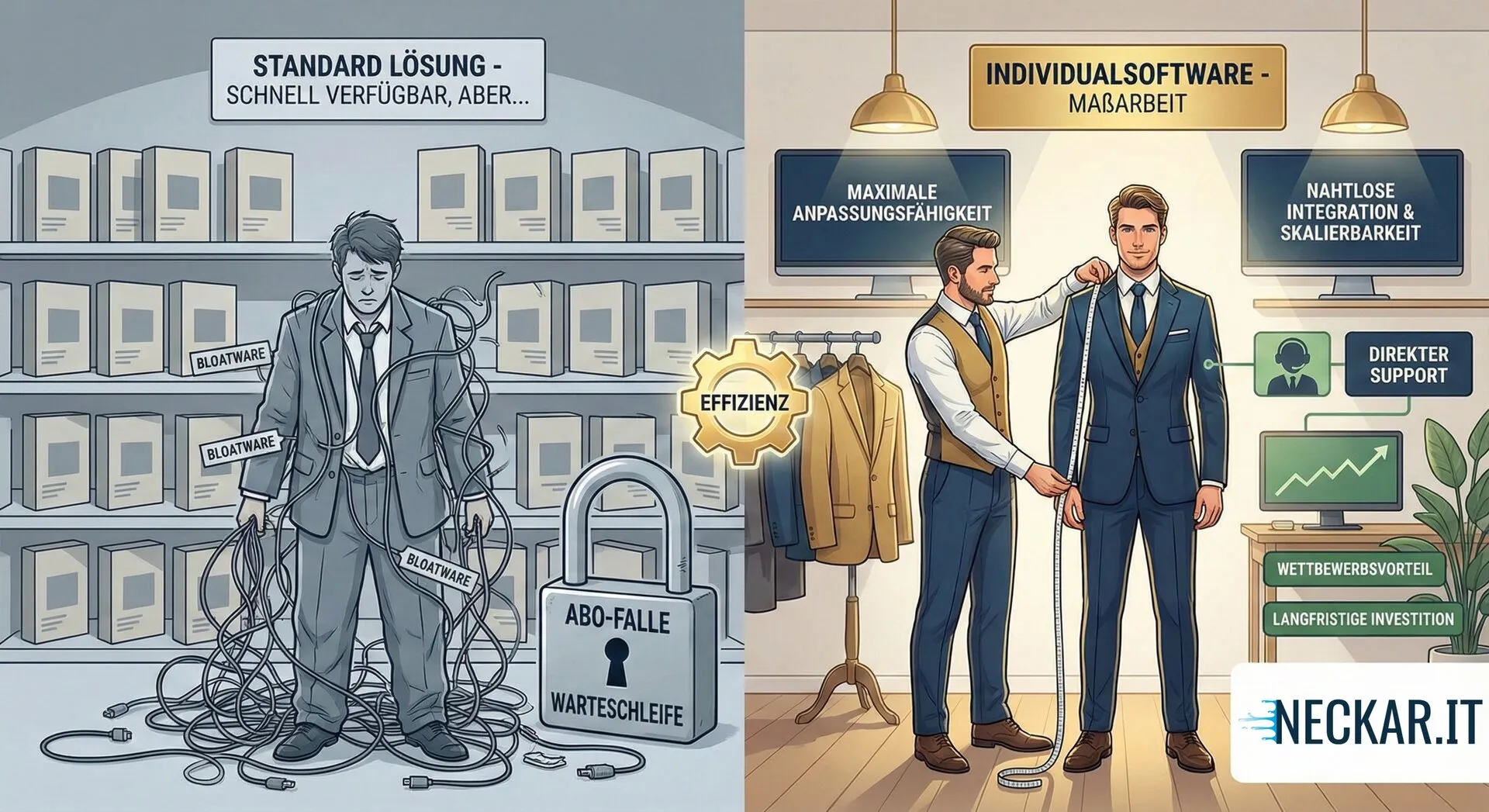
Individualsoftware Vorteile im Vergleich zu Standardsoftware
Standard oder Maßarbeit? 5 Vorteile von Individualsoftware: Von Kosteneffizienz bis Wettbewerbsvorteil. Jetzt informieren!